������������1������������2������������3������������4����������������...�������333230快速且无监督的动作边界检测用于动作分割0西北工业
”动作边界检测 无监督动作分割 高效性 相似性检测 聚类算法“ 的搜索结果
无监督聚类是一种机器学习技术,用于将数据分组成不同的类别,而无需提前标记或指导。在无监督聚类中,算法通过分析数据之间的相似性和差异性,自动将数据划分为具有相似特征的组。
分类算法是一种监督学习(Supervised Learning)方法,它需要一个已知的类别标签的训练数据集,通过学习这个数据集来预测新的数据点的类别。例如,在电子邮件过滤系统中,分类算法可以学习如何区分垃圾邮件和非垃圾...
目标检测(Object Detection)是计算机视觉领域的重要研究方向之一,它旨在通过对图像或视频中出现的物体及其位置进行精确定位并进行分类,从而完成对图像内容的理解和分析。最常见的方法是利用计算机视觉领域最先进...
文末附行业细分群现有的 3D 实例分割方法以自下而上的设计为主——手动微调算法将点分组为簇,然后是细化网络。然而,由于依赖于聚类的质量,当(1)具有相同语义类的附近对象被打包在一起,或(2)具有松散连接区域...
25710多视角共分割和聚类变压器的无监督分层语义分割0Tsung-Wei Ke Jyh-Jing Hwang Yunhui Guo Xudong Wang Stella X. Yu UCBerkeley / ICSI0摘要0无监督语义分割旨在发现在图像内部和图像之间捕捉类别...
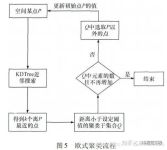
本次实验是一场聚类算法的深度探索之旅,涵盖了K-means、K-medoids、DBSCAN和凝聚聚类等引人注目的算法。K-means通过巧妙的迭代将样本点划分到K个簇,并通过聚类中心的不断更新优化结果。尽管简单高效,但对初始...
聚类分析是一种典型的无监督学习, 用于对未知类别的样本进行划分,将它们按照一定的规则划分成若干个类族,把相似(距高相近)的样本聚在同一个类簇中, 把不相似的样本分为不同类簇,从而揭示样本之间内在的性质以及...
3293mAPH(%)基于几何感知的对比度和聚类协调的自监督3D目标检测梁寒雪1*,蒋晨涵2*,冯大鹏3,陈鑫4,杭旭2,梁晓丹3†,张伟2,李振国2,Luc Van Gool 11苏黎世联邦理工学院2华为诺亚摘要6260当前的3D对象检测...

2014年之前可以称为传统目标检测时代,其最具代表性的方法有VJ检测器[19]、HOG检测器[20]、DPM检测器[21]。它们有着共同的特点就是使用手工设计的特征描述子如方向梯度直方图[20](Histogramof Oriented Gradient,...
聚类算法:K-means、K-means++;聚类算法评估;特征降维:特征选择(Pearson相关系数、Spearman相关系数)、PCA主成分分析


点击上方,选择星标,每天给你送干货!来源:海豚数据科学实验室著作权归作者所有,本文仅作学术分享,若侵权,请联系后台删文处理聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现...

各种聚类算法的介绍和比较
标签: 算法

在第一个聚类阶段,使用具有颜色相似性和几何约束的DBSCAN算法对像素进行快速聚类,然后在第二个合并阶段,通过颜色和空间特征定义的距离度量,将小簇按其邻域合并为超像素。为了在这两个步骤中获得更好的超像素,...

10336无监督特征表示的实例相似性学习王紫薇1,2,3,王云松1,吴子怡1,陆继文1,2,3 *,周杰1,2,31清华大学自动化系2智能技术与系统国家重点实验室3北京国家信息科学技术研究中心{wang-zw18,wangys16} @ mails...

K-means是一种常见的聚类算法,用于将数据集划分为K个不同的簇(cluster),每个簇包含相似的数据点。基于本人的理解浅谈了一下k-means聚类算法。
K均值聚类算法是一种常用的无监督学习算法,用于将数据集中的数据对象分成不同的组或类别。该算法的核心思想是通过计算数据对象之间的相似性距离,将相似的对象聚集在一起,形成一个簇(cluster)。K均值聚类算法是...
本章首先介绍了本文工作所使用的目标检测框架Faster RCNN,然后阐述了领域自适应目标检测的相关理论基础,最后介绍本文所用到的目标检测评价指标。Faster RCNN[10]是经典的两步目标检测模型,该模型提出用RPN来...
此外,在生物 基因、物体形态识别等与时间顺序无明显关联的数据类型中,也可以按照一定的规则将其转换成时间序列模式,进而利用时间序列数据挖掘技术进行分析。鉴于时间序列具有数据量大、数据维度高、持续积累等...
聚类分析是研究发现最具有代表性的簇原型的技术。注意:簇的定义是不精确的,而最好的定义依赖于数据的特征和期望的结果。聚类分析与其他将数据对象分组的技术有关。 1聚类类型 不同的聚类类型: 层次的(嵌套的...
## 1.2 聚类算法在无监督学习中的重要性 聚类算法是无监督学习中的重要方法,主要用于将数据集划分为若干个具有相似特征的类别或簇。聚类算法可以帮助我们发现数据的内在结构、模式和规律,从而为后续的数据分析和...

推荐文章
- C++语法基础--标准库类型--bitset-程序员宅基地
- [C++] 第三方线程池库BS::thread_pool介绍和使用-程序员宅基地
- 如何使用openssl dgst生成哈希、签名、验签-程序员宅基地
- ios---剪裁圆形图片方法_ios软件圆形剪裁-程序员宅基地
- No module named 'matplotlib.finance'及name 'candlestick_ochl' is not defined强力解决办法-程序员宅基地
- 基于java快递代取计算机毕业设计源码+系统+lw文档+mysql数据库+调试部署_快递企业涉及到的计算机语言-程序员宅基地
- RedisTemplate与zset redis_redistemplate zset-程序员宅基地
- 服务器虚拟化培训计划,vmware虚拟机使用培训(一)概要.ppt-程序员宅基地
- application/x-www-form-urlencoded方式对post请求传参-程序员宅基地
- 网络安全常见十大漏洞总结(原理、危害、防御)-程序员宅基地